Dataset Samples

1. We introduce ViCaS, a human-annotated video dataset containing thousands of videos with detailed captions, along with pixel-precise segmentation masks for salient objects with phrase-grounding to the caption.
2. Our benchmark contains two tasks: (a) Video Captioning, which evaluates high-level video understanding, and (b) Language-Guided Video Instance Segmentation (LGVIS), which evaluates finegrained, pixel-level localization based on text prompts.
3. We propose Video-LLaVA-Seg, an effective baseline architecture that can tackle both of our benchmark tasks with a single, end-to-end trained model.
Recent advances in multimodal large language models (MLLMs) have expanded research in video understanding, primarily focusing on high-level tasks such as video captioning and question-answering. Meanwhile, a smaller body of work addresses dense, pixel-precise segmentation tasks, which typically involve category-guided or referral-based object segmentation. Although both research directions are essential for developing models with human-level video comprehension, they have largely evolved separately, with distinct benchmarks and architectures. This paper aims to unify these efforts by introducing ViCaS, a new dataset containing thousands of challenging videos, each annotated with detailed, human-written captions and temporally consistent, pixel-accurate masks for multiple objects with phrase grounding. Our benchmark evaluates models on both holistic/high-level understanding and language-guided, pixel-precise segmentation. We also present carefully validated evaluation measures and propose an effective model architecture that can tackle our benchmark.
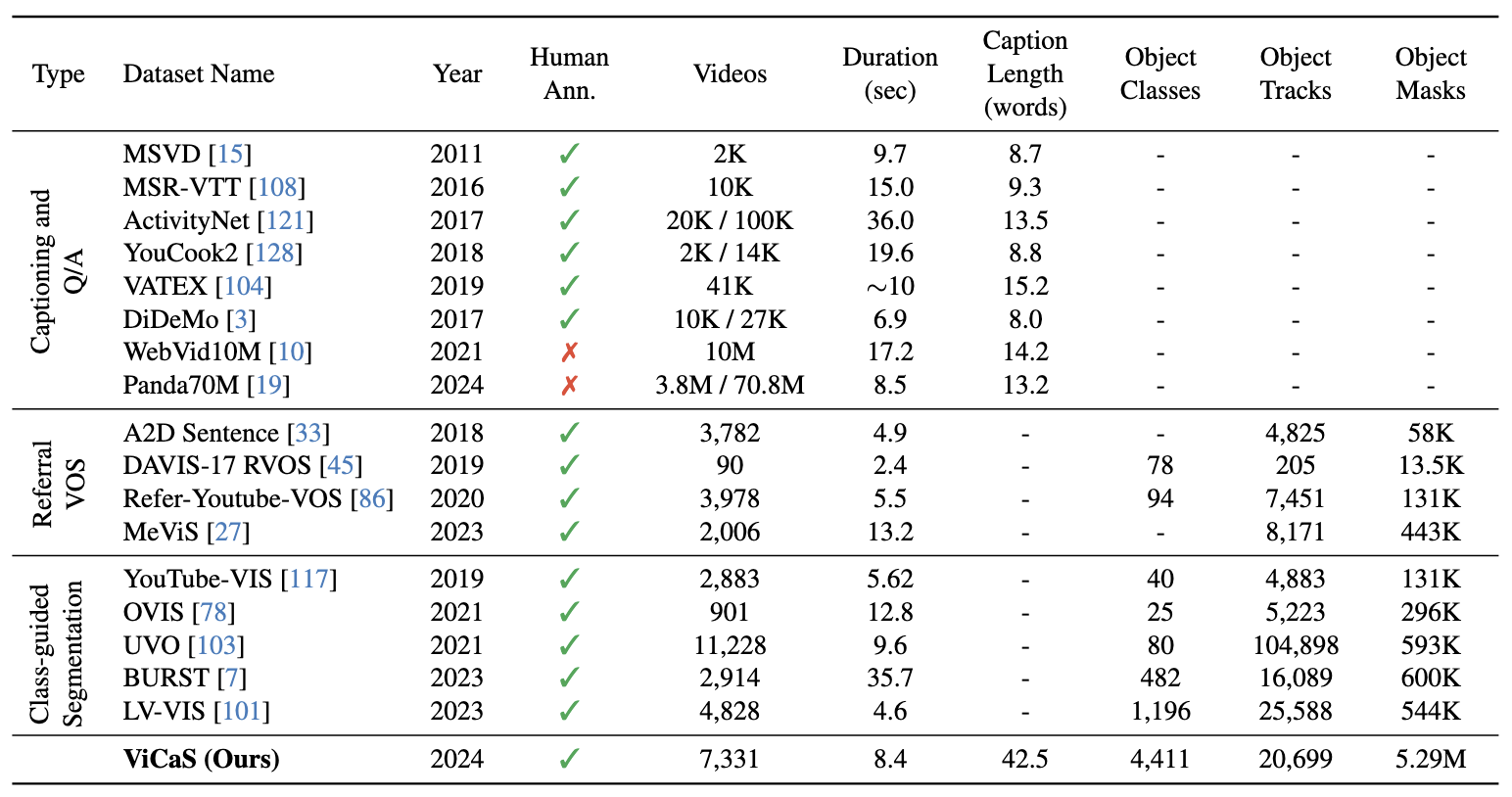
The table compares ViCaS to existing datasets for video captioning, Referral Video Object Segmentation, and more classical category-guided video segmentation datasets.
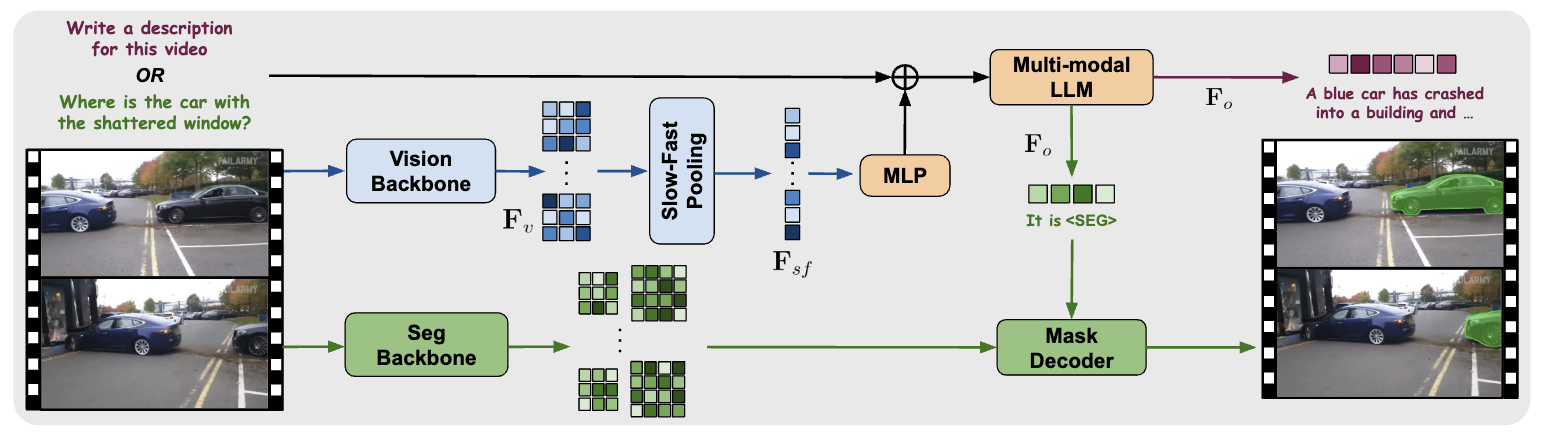
The vision backbone and projection MLP encode the input video frames into a set of features Fsf which are concatenated with the text embeddings and input to the LLM. For Video Captioning, the output Fo is decoded into text. For LG-VIS, the [SEG] token in Fo is applied to the mask decoder along with multi-scale features from the segmentation backbone.
@article{athar2024vicas,
author = {Ali Athar, Xueqing Deng, Liang-Chieh Chen},
title = {ViCaS: A Dataset for Combining Holistic and Pixel-level Video Understanding using Captions with Grounded Segmentation},
journal = {CVPR},
year = {2025}
}